The new scheme developed through the Emurgo-Ergo partnership will see oracle pools – core blockchain infrastructure – run as a public service, accessible by any dApp and developer, free at the point of use.
Oracles are a crucial element of DeFi infrastructure. They are the bridge between the siloed world of the blockchain and data from the real world, and so are vital for DeFi to reach its full potential. The integrity of major use cases, including stablecoins and lending platforms, rely on oracles that are fit for purpose.
Current oracle implementations fall short of the ideal. One of the first projects undertaken as part of the Emurgo-Ergo partnership is research into Oracle Pools: a new way of bringing data from the outside world into the blockchain, and making it readily available for any dApp.
The shortcomings of current implementations
Oracles already underpin many decentralised applications on Ethereum, and typically work in the following way:
- A dApp wishes to acquire information from the outside world and makes a request to an oracle by paying into its smart contract (payments are typically made using a dedicated oracle token).
- The oracle obtains the data and submits it back to the contract that called it via a separate transaction.
- The information is sent solely to the dApp that requested it, and no one else can use that data without paying.
While this works relatively well, typical oracles can essentially be considered as private services that employ a ‘pay-to-play’ model. As this was clearly insufficient for many use cases, the concept of data feeds was developed in order to improve the user experience for common pricing information.
Current data feeds on Ethereum, however, tend to be implemented in a very trusted manner. They lack a generalized approach that provides assurance about the reliability of the data, both in regards to its accuracy as well as its posting schedule. Furthermore, such approaches tend to have no clear decentralized funding mechanism to make them sustainable over the long term, but instead rely on sponsorship by centralized actors.
Ergo and Emurgo’s view is that oracles are too important to be restricted in this way. They should be public infrastructure for the DeFi sector. The oracle pools model developed through the partnership addresses this need.
Oracle pool design
Ergo’s UTXO model offers benefits for oracle systems that were not previously available. Pools of oracles act to decentralise the provision of data, ensuring that both the process and the data itself are more reliable.
At their simplest, oracle pools break up time into fixed epochs (e.g. 6 hours), which are subdivided into blocks (e.g. 180 two-minute blocks). The group of oracles within the pool agree on the data sources and each post their data points to the blockchain in their own UTXO.
At the end of an epoch these data points are averaged, after removing outliers, in a final transaction which reads each data point UTXO. This results in the oracle pool producing a new finalized datapoint, and moving forward towards the next epoch.
This is not particularly complicated to understand, but lays a solid foundation. One critical factor to note is that the whole process occurs on-chain. Moreover, the use of UTXOs enables the addition of incentives and governance mechanisms, allowing far greater sophistication and flexibility of oracle pools and data provision than was previously possible.
Building on the foundation of UTXO-based oracle pools
As mentioned previously, it is possible to implement incentives and penalties in the pools to help ensure the quality and timeliness of the data they provide. Oracles put up collateral – a certain amount of ADA, ERG, etc – to participate in a pool. Coins are removed from their balance (‘stake slashing’) if they fail to do their job properly, e.g. if they fail to collect other oracles’ datapoints, if they submit a wildly inaccurate datapoint (an outlier), or if they do not submit a datapoint in a timely fashion. This ensures that oracles do their job well. The collateral is the blockchain’s native currency, not a separate token, simplifying matters and improving economic incentives.
The model also enables governance voting to determine key parameters for oracle pools. The governance community can decide variables such as how long the epoch is, how much oracles get paid for posting valid data points, the minimum collateral they require, the number of oracles per pool, and so on. There is a high degree of flexibility, and parameters can be changed based on current needs. New oracles can be invited to a pool, others removed, and so on.
This model incorporates a strict posting schedule (epochs) and governance directly, which projects such as Chainlink do not have. Effectively, oracle pools become mini DAOs that aim to provide the best service and can compete according to the service they provide in a free market, thereby improving the overall quality of data that everyone uses.
Payment model
The UTXO model means that results are posted to the blockchain and are available for anyone to use for the cost of a transaction fee. This is not the standard pay-to-play approach: dApps can access data for next to nothing. Furthermore, this access to oracle pool data scales cleanly and at no extra cost even if more complicated protocols are built on top of oracle pools (such as hierarchies, or time-weighted averages).
Oracle pools are paid for by the dApps that use them over time. While everyone can use oracles and everyone who uses them has an incentive to fund them, this costs very little – a small percentage of extra fees on a given dApp. It is expected that these oracle pool payments will be implemented in major dApps, therefore ensuring that pools always have the funds they need to function.
It makes most sense that large, flagship applications like stablecoins, wallets, decentralised exchanges, lending protocols, and so on, would pay for key oracle pools – in much the same way that key blockchain companies run their own nodes. It’s part of their operation and part of their Corporate Social Responsibility, to borrow a term from the business world. It’s how they guarantee access to the data they need, help keep the ecosystem healthy, and show they are serious about staying the distance in the DeFi sector. At the same time, oracle pools are designed so that even small actors can run their own and have a funding mechanism baked in if they find a sufficient user base.
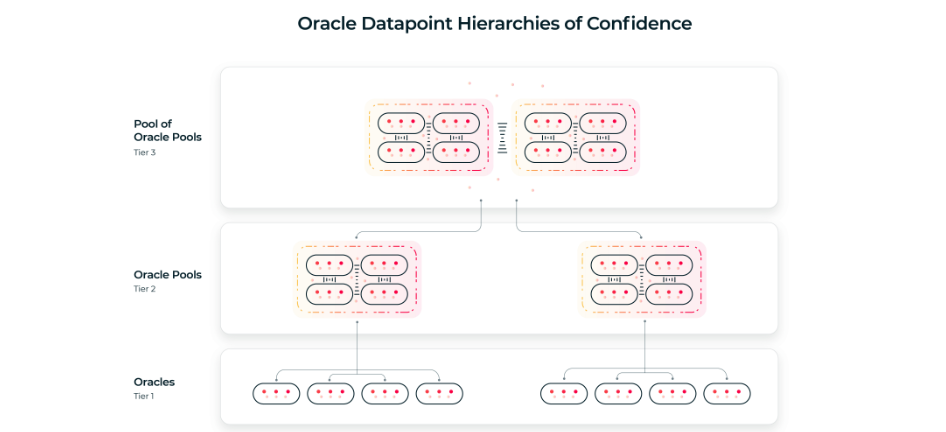
The pools model means the funds paid can be disbursed effectively, within a range of different pool structures. It would be possible to have a pool-of-pools, with several oracle pools aggregating data and those results being pooled and averaged. The payment goes to the top pool, which pays funds out to the next pools down in the hierarchy according to how reliable they are, and those pools distribute funds to the most reliable oracles within them. The main advantage is that it is simple for the user, since only one payment to the top pool is required.
There is also scope for using signed data – data from trusted entities like large exchanges. These can submit signed data to ‘first-to-post’ pools, where the funds are distributed to the first oracle to record data to the blockchain; because they are trusted, the averaging process is not necessary. Or there can be pools that aggregate partially signed and partially unsigned data, giving the best of both worlds. Signed and unsigned data points can be pooled and brought together into a single datapoint, and payouts can still be made cleanly by paying the top pool.
This is the first implementation to come from the Emurgo-Ergo collaboration: the first steps in building out the UTXO-based DeFi ecosystem. There will be much more to come, and new developments promise to be very exciting.
For further background, watch Emurgo researcher Robert Kornacki explain oracle pools.